1. Primers controls
1.1. SIGSTOP/SIGCONT, foreground/background, thread_suspend/thread_resume
SIGSTOP/SIGCONT, foreground/background, thread_suspend/thread_resume
-
Quines semblances hi ha entre SIGSTOP/SIGCONT i thread_suspend/thread_resume? Explica-les
Resposta
-
Quines diferències hi ha entre SIGSTOP/SIGCONT i thread_suspend/thread_resume? Explica-les
Resposta
-
Quines semblances hi ha entre foreground/background i thread_resume? Explica-les
Resposta
-
Quines diferències hi ha entre foreground/background i thread_resume? Explica-les
Resposta
-
Explica una situació en la qual es vegi clara la utilitat de fer SIGSTOP i background (bg) a un procés
Resposta
1.2. Espais d’acdreces i més …
Tenim dos processos corrent en el sistema, que contenen la mateixa aplicació, i, mirant el seu espai d’adreces amb la comanda de Linux “pmap” veiem el següent per a cadascun, quan sabem que aproximadament són en el mateix punt de l’execució. En aquests mapes de memòria les mides de les regions estan en KBytes:
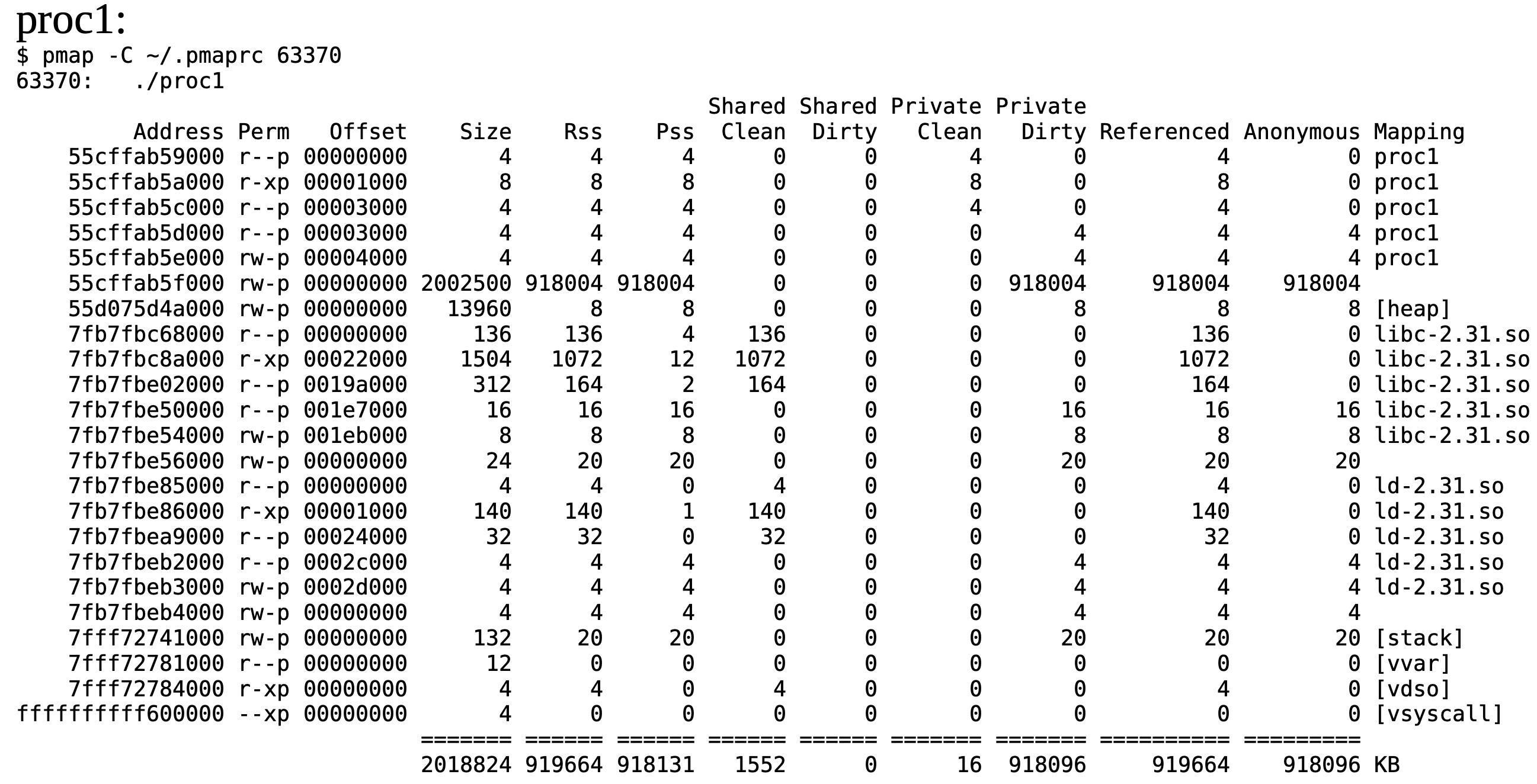
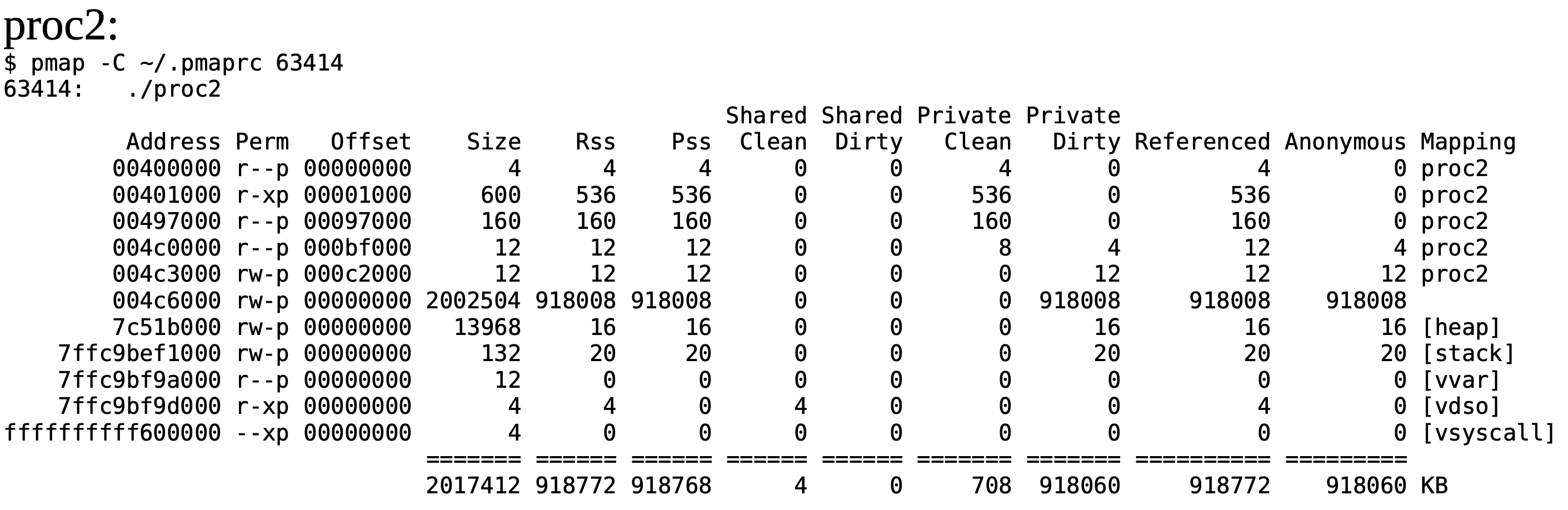
-
Quina penseu que és la principal diferència entre ells? En aquesta diferència, quina participació hi té el procés de compilació?
Resposta
-
Parlem d’alguns detalls:
-
Les adreces on tenim proc1 i proc2 són molt diferents. Dóna una explicació a per què són tan diferents
Resposta
-
Segons els permisos de les regions, quines regions de memòria tenen proc1 i proc2 (fixa’t en les regions de Mapping proc1 i Mapping proc2 exclusivament)? Pots identificar quines són de codi i quines de dades? Entre les de dades, pots distingir-les segons alguna propietat?
Resposta
-
En el procés de proc1, què són libc-2.31.so i ld-2.31.so?
Resposta
-
Per la regió de mida aproximada 2002500 bytes…
-
Quina quantitat de dades s’han accedit realment fins aquest punt de l’execució?
Resposta
-
Aquesta quantitat de dades que hem accedit, s’ha fet per llegir-les o escriure-les? Com ho saps?
Resposta
-
-
Què és la regió [heap]?
Resposta
-
Què és la regió [stack]?
Resposta
-
1.3. Abstraccions
Observa detingudament el dibuix adjunt i respon a les preguntes raonadament.
-
Quina abstracció creus que representen els cubs?
Resposta
-
Anomena una crida al sistema que serveixi per crear aquestes abstraccions. Especifica de quin sistema operatiu.
Resposta
-
Els cubs formen part d’una altra abstracció. Quina?
Resposta
-
Anomena una crida al sistema que serveixi per crear aquesta abstracció. Especifica de quin sistema operatiu
Resposta
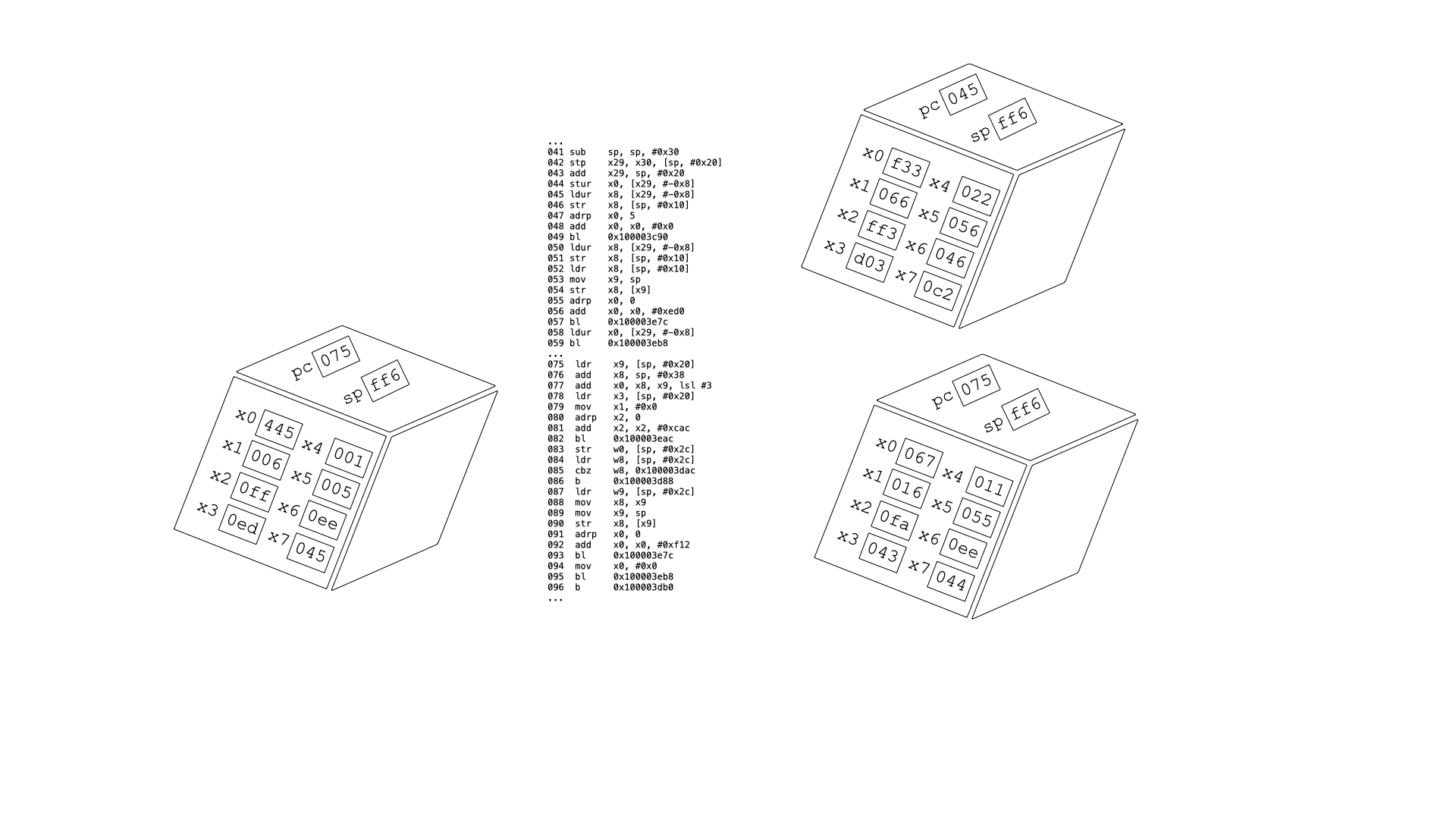
1.4. Puzzle de codi
-
Tenim aquestes peces del codi de creació d’un BSD thread a macOS que inclou l’assignació de memòria per a la pila del nou thread. Ordena’ls en l’ordre que consideris correcte. Raona breument la teva elecció.
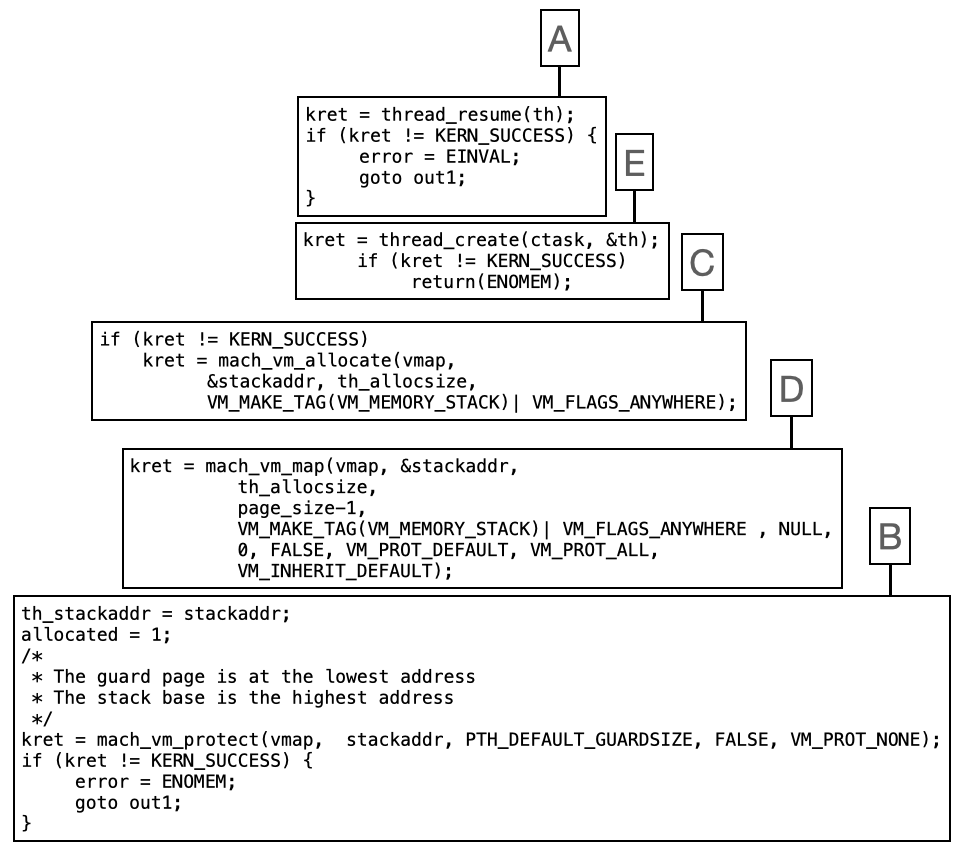
Resposta
1.5. Afinitats
En un sistema Linux, obtenim la següent informació:
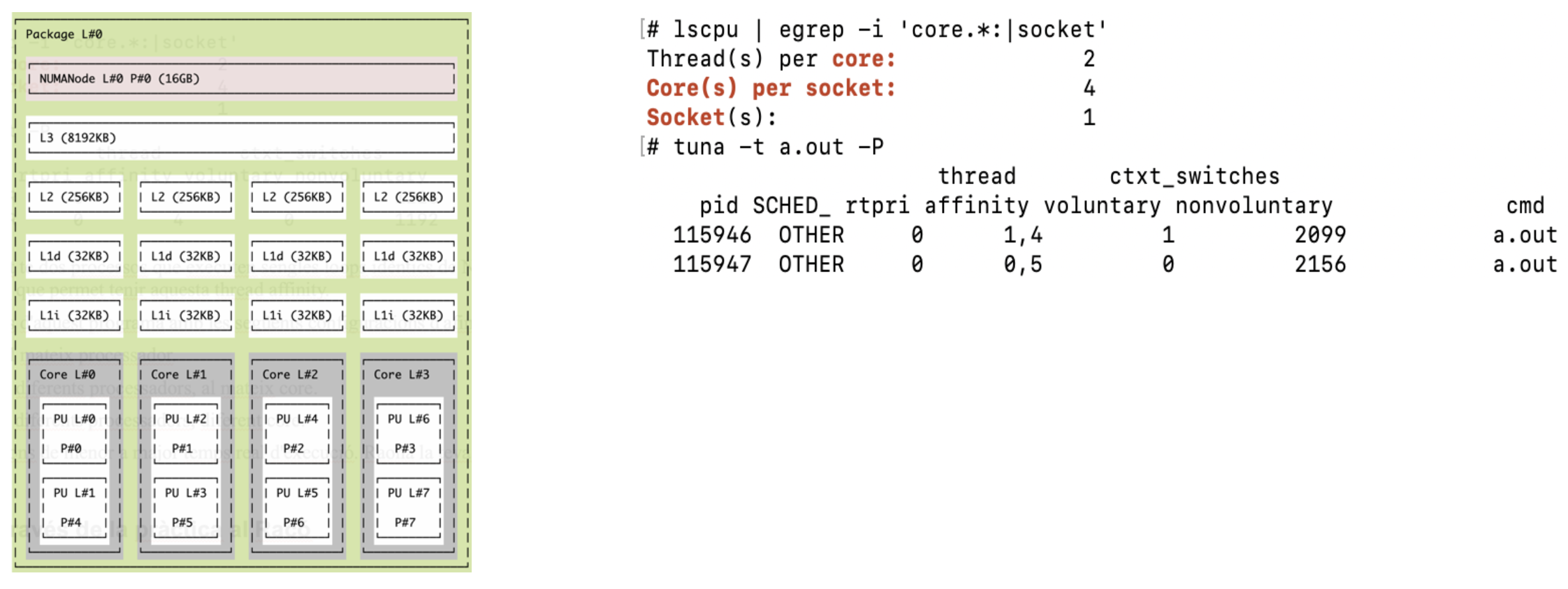
-
El programa a.out té dos processos que executen sengles loops idèntics de N iteracions. Escriu el tros de codi del fill que permet tenir aquesta thread affinity.
Resposta
-
Fem 3 execucions d’aquest programa amb les següents configuracions d’afinitat:
a) Pare i fill al mateix processador (al 0).
b) Pare i fill a diferents processadors, al mateix core (al 0 i al 1).
c) Pare i fill a diferents processadors, diferent core (0 i 3).
Ordena les 3 execucions de menor a major temps real d’execució. Raona la teva respostaResposta
1.6. Abstraccions a Mach
-
Enumera i explica tres abstraccions de Mach. Indica una crida al sistema
relacionada amb cadascun dels tres conceptes.Resposta
1.7. Comparativa: sbrk vs mmap
-
Aquestes dues crides permeten demanar memòria:
#include <unistd.h> // change data segment size void *sbrk(intptr_t increment); #include <sys/mman.h> // allocate memory, map files or devices into memory void *mmap(void *addr,size_t length,int prot,int flags,int fd,off_t offset);
Fes una comparació de les seves funcionalitats, basada en dibuixos de l’espai d’adreces d’un procés.
Resposta
La funció sbrk() modifica la mida del segment de dades tot canviant el program break, que defineix el final del data segment del procés. Incrementar el program break implica alocatar memòria pel procés, mentre que decrementar-lo implica alliberar memòria. La crida al sistema sbrk() retorna l’anterior program break.
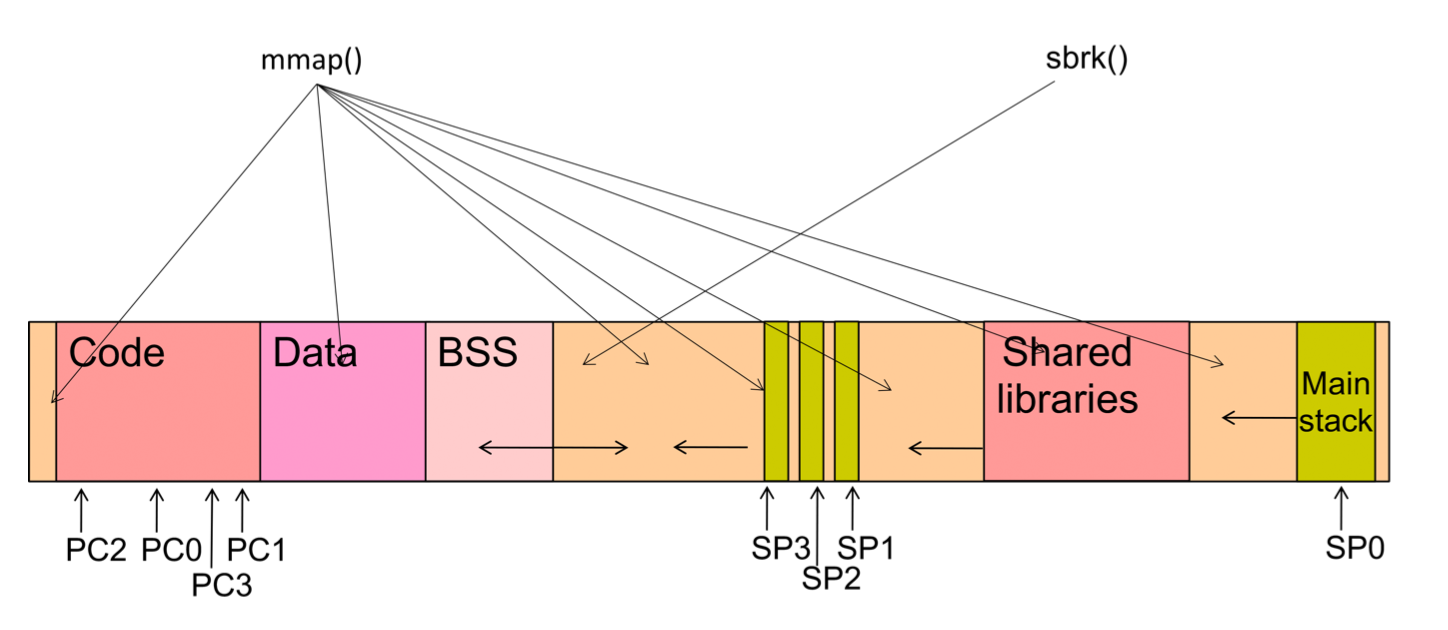
La funció mmap(), mapeja fitxers o dispositius a memòria tot creant un nou mapatge a la memòria virtual del procés. L’adreça d’inici la pot rebre com a par`metre, però si aquest és null, el kernel escull la nova adreça. El mapatge es crearà en un límit de pàgina proper. La crida al sistema mmap() retorna l’dreça del nou mapping.
1.8. Clones
-
Explica les diferències que hi ha entre els clones de Linux i els threads de Mach. Quines diferències hi ha entre un thread de Mach i un PThread?
Resposta
1.9. Thread safe
A continuació tens un codi que no és thread safe.
while (lock==1) ; //spin
lock = 1;
// regio critica de codi
lock = 0;Enumera i explica quins aspectes problemàtics li trobes i proposa un codi alternatiu.
Resposta
1.10. Mach
-
Mach ofereix cinc abstraccions de programació que són el maons bàsics del sistema. D’aquestes, et
demanem que defineixis només les quatre primitives següents: Thread, Task, Message i Port.Resposta
1.11. Linux
-
A Linux existeix la crida al sistema int
sched_setaffinity(pid_t pid, size_t cpusetsize, const cpu_set_t *mask);-
Quins efectes tindrà l’execució de les següents línies de codi per la resta del programa?
CPU_ZERO(&mask); CPU_SET(2, &mask); CPU_SET(1, &mask); sched_setaffinity (getpid(), 4, &mask);Resposta
-
Descriu un escenari a on un thread en concret aprofiti aquesta syscall per millorar el seu rendiment.
Resposta
-
Descriu un escenari a on els threads d’un procés en concret aprofitin aquesta syscall per millorar el seu rendiment.
Resposta
-
A POSIX, existeix la crida
int pthread_setaffinity_np(pthread_t thread, size_t cpusetsize, const cpu_set_t *cpuset), ¿quan seria recomanable fer-la servir en comptes desched_setaffinity(…)?Resposta
-
1.12. Threads
-
Per a cadascuna de les següents línies de codi, indica quina funció de més alt nivell estan implementant i a quin sistema operatiu.
-
CreateThread( (LPSECURITY_ATTRIBUTES)security, stacksize, _threadstartex, (LPVOID)ptd, createflag, (LPDWORD)thrdaddr))Resposta
-
clone(child_stack,
CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD|CLONE_SYSVSEM|CLONE
_SETTLS|CLONE_PARENT_SETTID|CLONE_CHILD_CLEARTID, parent_tid, tls, child_tidptr)Resposta
-
clone(NULL, NULL, SIG_CHLD, NULL)Resposta
-
thread_create(self, &kernel_thread)Resposta
-
1.13. Eines de desenvolupament
-
Entre les eines de desenvolupament tenim l’enllaçador (linker). GNU proporciona 2 enllaçadors, segons la transparència que vam veure a classe:
ld / gold → linker
A la Wikipedia trobem aquesta explicació:
In software engineering, gold is a linker for ELF files. It became an official GNU package and was added to binutils in March, 2008 and first released in binutils version 2.19. Gold was developed by Ian Lance Taylor and a small team at Google. The motivation for writing gold was to make a linker that is faster than the GNU linker, especially for large applications coded in C++. Unlike the GNU linker, gold doesn’t use the BFD library to process object files. While this limits the object file formats it can process to ELF only, it is also claimed to result in a cleaner and faster implementation without an additional abstraction layer. The author cited complete removal of BFD as a reason to create a new linker from scratch rather than incrementally improve the GNU linker. This rewrite also fixes some bugs in old ld that break ELF files in various minor ways. To specify gold in a makefile, set the LD or LD environmental variable to ld.gold. To specify gold through a compiler option, one can use the gcc option -fuse-ld=gold.
Responeu:
-
Per què tenim dues versions del “linker”?
Resposta
-
Quines limitacions té el
gold, si el comparem amb l'ld?Resposta
-
En cas de tenir una aplicació formada per multitud de fitxers (C i/o C++) - per tant, usant compilació separada, i un Makefile, i per la qual volem generar un fitxer executable en format ELF, ordeneu per ordre de preferència aquestes alternatives que tenim per enllaçar-los:
c1
export LD=ld.gold
makec2
export CFLAGS=”-fuse-ld=gold”
makec3
makec4
gcc -fuse-ld=ld *.c *.cpp`Expliqueu el perquè de l’ordre que heu decidit.
Resposta
1.14. User space pagers
-
Volem dissenyar un sistema de memòria compartida distribuïda, fent servir el model de Mach. Quin paper podrien tenir els object managers en aquest disseny? Descriu, pas a pas, com es resol una fallada de pàgina a Mach. Les paraules memory_object, vm_map i vm_allocate han d’apareixer a la teva resposta.
Resposta
1.15. Operating System
-
Hi ha qui ha identificat l’objectiu d’un sistema operatiu com el de proveir un entorn en el qual un usuari pugui executar programes en un ordinador de manera convenient i eficient.
Hi estàs d’acord? Desenvolupa breument els teus arguments. Quin creus més prioritari dels dos objectius (convenient, eficient)? Creus necessària l’existència d’un SO pel bon funcionament del sistema (entenent per sistema el conjunt de hardware, SO, programes i usuaris). Finalment, defineix sistema operatiu (sent coherent amb els teus arguments).
Resposta
1.16. KBuild
-
Explica què són les crides al sistema (
system calls), quin paper juguen en la definició d’un sistema operatiu. Com i quan (temps d’execució o de compilació) es pot afegir al kernel una crida al sistema? Com es fa la comunicació entre el kernel i el procés que fa la crida? Contextualitza el teu raonament pels casos de Linux i Mach. Pots ajudar-te d’aquest esquema i aquest codi per guiar la teva explicació.
mov rax, 0x2000004 ; sys_write call id
mov rdi, 1 ; STDOUT fd
mov rsi, usrBuf ; buffer to print
mov rdx, usrBufLen ; length of buffer
syscall ; make the syscallResposta
2. Segons controls
2.1. Què és un Sistema Operatiu?
-
Al 1982 es va llançar el mercat oficialment el MSDOS, el sistema operatiu del IBM PC i ordinadors compatibles. Aquesta màquina tenia un processador Intel 8088, de 8 bits i només un mode d’execució. A continuació mostrem un petit fragment del codi del MSDOS:
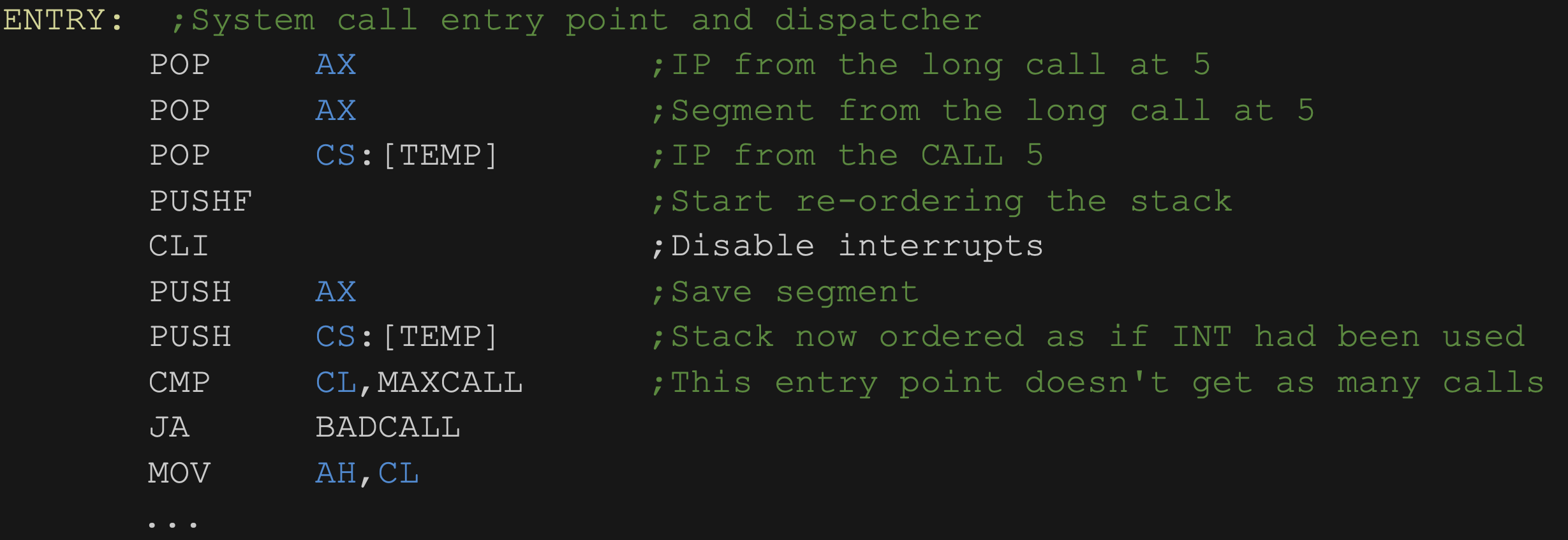
Dóna una definició de Sistema Operatiu, identificant els objectius principals que hauria de complir. Contextualitza la teva definició de sistema operatiu amb el MSDOS. Creus que aquest software compleix els teus criteris? Linux va sortir 9 anys més tard, sobre un Intel 80386, un processador de 32 bits amb 4 modes d’execució. ¿Quins dels objectius que has descrit es va veure beneficiat per la diferència de hardware respecte al MSDOS?Resposta
2.2. SAN o NAS?
-
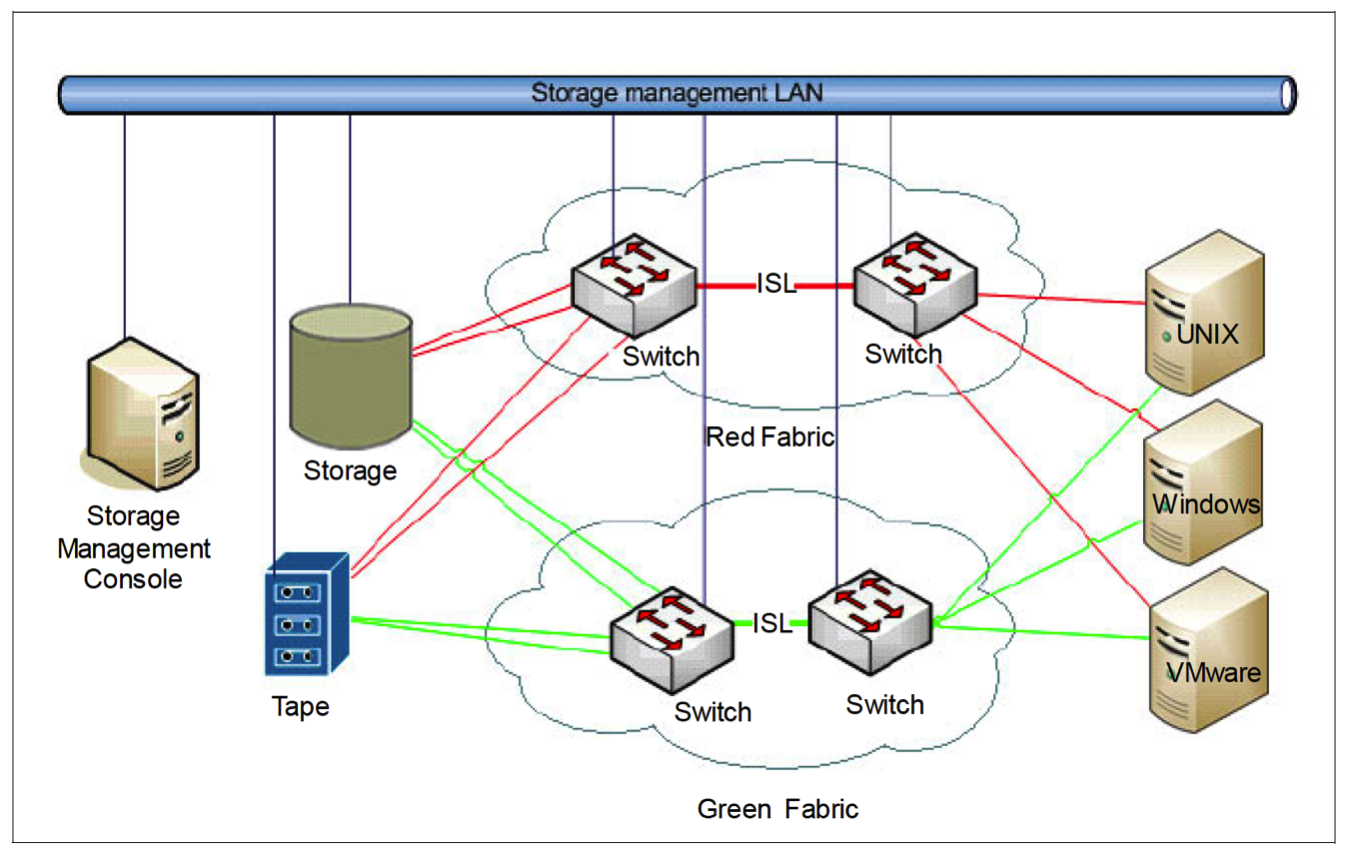
A la figura teniu l’esquema d’una xarxa, a on storage és la unitat d’emmagatzematge que guarda els fitxers dels usuaris de diferents sistemes operatius.
-
¿Quin entorn creus que representa, SAN o NAS?
Resposta
-
Explica breument, basant-te en el dibuix, com funciona
Resposta
-
Quina és la diferència fonamental entre SAN i NAS?
Resposta
-
Cita algun sistema de fitxers pensat explícitament per aquest entorn.
Resposta
2.3. Enginyeria Inversa
-
Hem executat la comanda
stracesobre un binari. A partir d’aquest extracte de la seva sortida, intenta deduir alguna de les crides de més alt nivell que s’han executat.
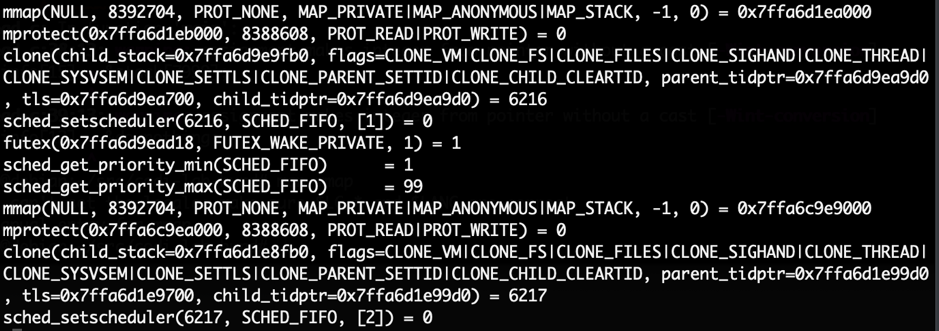
Resposta
2.4. Memòria amb mmap
-
La crida al sistema
mmap(), segons el manual, allocate memory, or map files or devices into memory , per tant, té funcionalitats semblants amalloc()iread(), respectivament.
Compara, per separat,mmap()amb cadascuna d’elles i assenyala situacions on faries servir una o l’altre.Resposta
2.5. Transferir dades
-
El sistema operatiu ha de transferir dades entre l’espai dels processos i el del sistema operatiu per tal de i) llegir informació dels dispositius amb seguretat i protecció i passar-la a l’usuari; o bé, ii) per llegir informació de l’espai d’usuari d’un procés i passar-la a dins del sistema operatiu per dur-la a un dispositiu. Així implementem les lectures i escriptures a dispositius, respectivament.
Una de les rutines típiques de UNIX/Linux per dur a terme aquesta tasca és:
long copy_to_user ( void __user * to, const void * from, unsigned long n );Aquesta funció rep el punter destí a l’espai d’usuari (“to”), el punter origen de la informació a l’espai de sistema (“from”) i la longitud en bytes que volem copiar (“n”). A més, retorna el número de bytes que no s’han pogut copiar, per exemple perquè s’ha trobat amb què una de les adreces de l’espai de l’usuari no és vàlida.
Per tant, si retorna 0 (zero) vol dir que tot ha anat bé. I si retorna una quantitat més gran que 0 (zero), vol dir que ha trobat un error en el byte “n - la quantitat retornada”. En aquest cas posa la variable d’error (“errno”) a EFAULT, per exemple, que és l’error que es retornarà a la crida a sistema que es trobi amb aquesta situació.
El dibuix que representa l’actuació d’aquesta funció és:

Responeu:
-
Doneu una possible implementació bàsica d’aquesta funció “copy_to_user”. Es valoraran les indicacions del control d’errors. Podeu usar una funció
bool bad_address (void * ptr);
que us retorna 1 (cert) si el punter “ptr” apunta a una adreça que l’usuari no és vàlida.Resposta
-
Tenint present el tema del com s’accedeix a les variables pròpies d’un thread (recordar la pràctica de Mach, exercicis 8 i 9), com podrieu implementar l’atribut “user” que s’aplica al punter que apunta a l’espai de l’usuari
(voiduser * to, en l’exemple)?Resposta
2.6. Suport per Temps Real
-
Classifica els següents escenaris com a hard, firm o soft realtime (1 punt)
-
Els tres threads del Mars Pathfinder.
-
Un servidor de vídeo descodifica els codis de temps per saber quan han d’aparèixer els fotogrames per pantalla. Si va tard, el fotograma no es mostra.
-
Una impressora d’injecció de tinta té un capçal d’impressió amb programari de control per dipositar la quantitat correcta de tinta en una part específica del paper. Si va tard, surt massa tinta.
-
Una consola de video-jocs calcula l’escena quan el personatge entra en ella. Si va tard, parts de l’escenari (textures) no es mostren correctament.
Resposta
-
-
Enumera i explica 2 funcions POSIX que t’ajudin a programar per temps real (1 punt).
Resposta
2.7. Memòria
-
La següent traça correspon a un procés Linux que ha demanat memòria dinàmica. Pots endevinar les quatre crides a funcions del codi font del programa? Pista: el procés ha obtingut tota la memòria demanada i no més.
$ strace -f ./a.out brk(NULL) = 0x560f5c04f000 brk(0x560f5c04f004) = 0x560f5c04f004 clone(child_stack=0x7fdf6a965fb0, flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD|CLONE_SYSVSEM|CLONE_SETTLS|CLONE_PARENT_SETTID|CLONE_CHILD_CLEARTIDstrace: Process 10371 attached , parent_tid=[10371], tls=0x7fdf6a966700, child_tidptr=0x7fdf6a9669d0) = 10371 [pid 10370] futex(0x7fdf6a9669d0, FUTEX_WAIT, 10371, NULL <unfinished ...> [pid 10371] futex(0x7fdf6a1651e0, FUTEX_WAKE_PRIVATE, 2147483647) = 0 [pid 10371] exit(0) = ? [pid 10370] <... futex resumed>) = 0 [pid 10371] +++ exited with 0 +++ exit_group(0) = ? +++ exited with 0 +++Resposta
-
El següent codi d’un programa Mach genera un error en executar-se (
Segmentation fault), però status sempre valKERN_SUCCESS. A què és degut?define SZ vm_page_size void dummy() { printf("Dummy funciona!\n"); exit(0); } int main() { vm_address_t regio; mach_port_t task_self = mach_task_self(); kern_return_t status; status = vm_allocate(task_self, ®io, SZ, TRUE); if (status != KERN_SUCCESS) printf("error assignant memoria.\n"); status = vm_protect(task_self, (vm_address_t) dummy, vm_page_size, FALSE, VM_PROT_NONE); if (status != KERN_SUCCESS) printf("error en protegir el segment de text.\n"); dummy(); printf("vaig acabant!\n"); exit(0); }Resposta
3. Tercers controls
3.1. Què és un Sistema Operatiu?
-
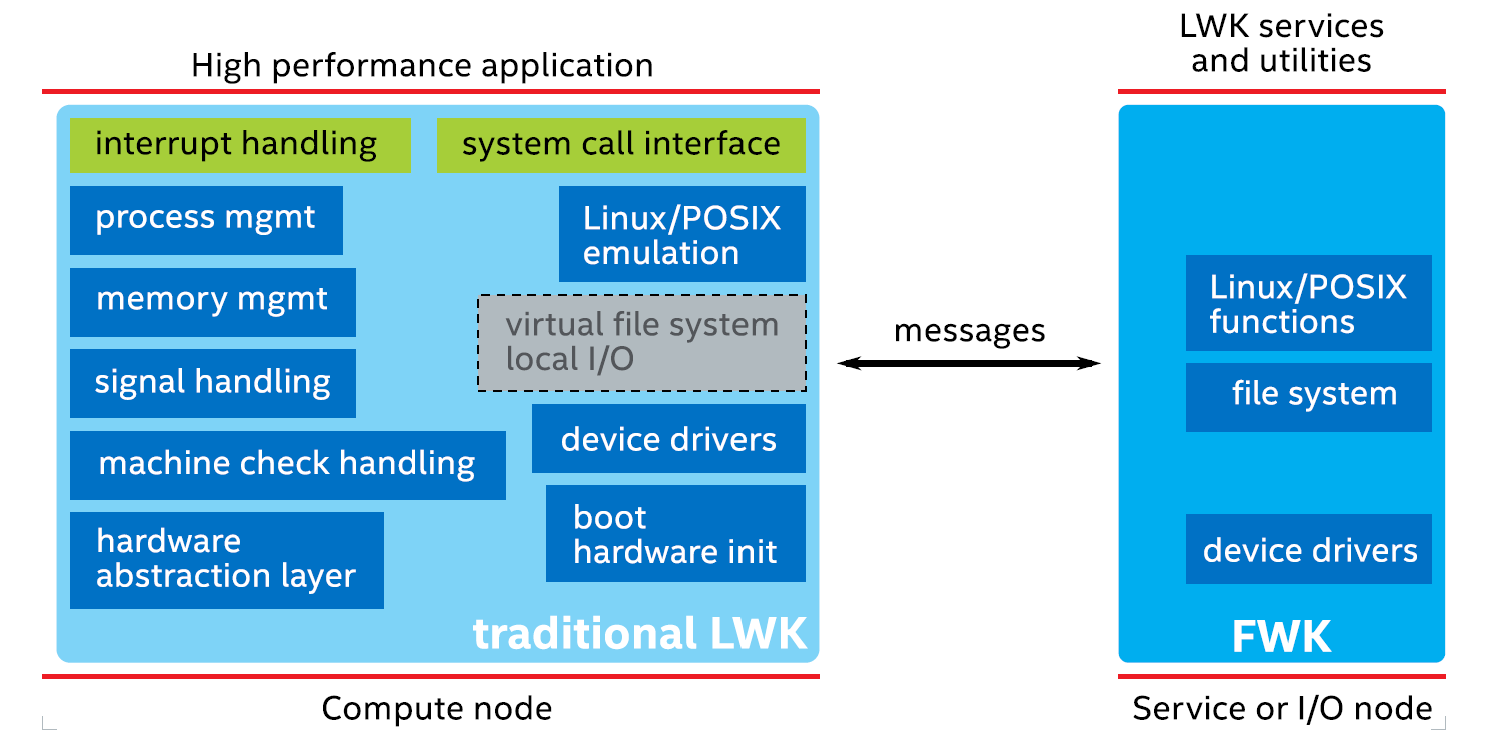
Per a la familia de supercomputadors BlueGene d’IBM es va implementar un lightweight kernel anomenat oficialment CNK (i Blrts extraoficialment). Suportava una gran quantitat de crides al sistema de Linux, tot i que només es dedicava a computació (Compute node a la figura); totes les crides d’entrada/sortida eren redireccionades cap a un únic node Linux (al Node Card de la figura).
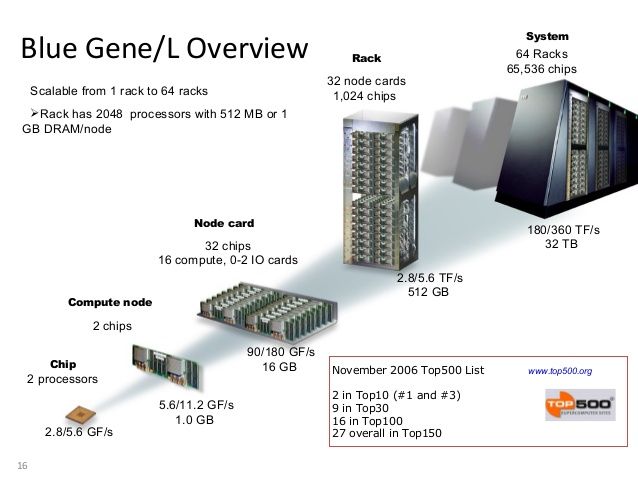
El CNK no permetia operacions fork/exec, en canvi, un compute node estava orientat a executar un procés MPI multithread, amb rigorosa afinitat. Tenint present la definició de Sistema Operatiu que has estudiat:
-
Creus que el CNK és un sistema operatiu?
Resposta
El CNK (Compute Node Kernel) és un sistema operatiu (protegeix al sistema i el gestiona per a un ús òptim) si fitem el hardware de la màquina al node sobre el que s’executa. De la resta del supercomputador, el CNK no sap res i per tant no pot fer d’interfície entre el programador i el supercomputador. El CNK és un sistema operatiu per al compute node, però necessita del FWK (Full Weight Kernel) per a comunicar-se amb l’exterior. En aquest sentit, CNK és un co-kernel.
-
En quina de les funcionalitats atribuïdes a un SO, el CNK té una mancança important?
Resposta
3.2. Mach tasks vs Unix processes
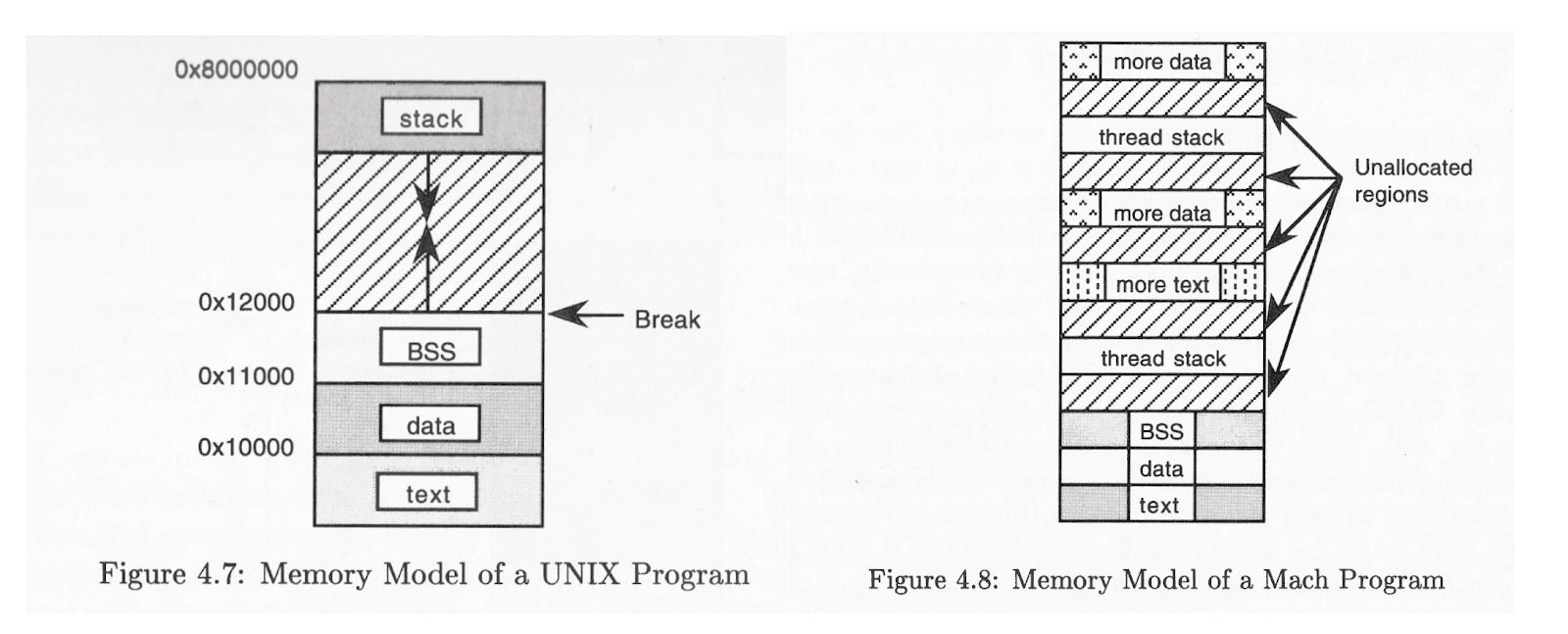
-
A les figures estan representats els models de memòria d’una task de Mach i d’un procés Unix. Aquesta representació data de mitjans dels anys 80.
-
Quina era (és) la syscall (o les syscalls) per crear l’abstracció d’aquest dibuix a Mach? I a Unix?
Resposta
Centrant-nos en el model de memòria, respón a les següents preguntes:
-
Quina és la diferència més significativa entre els dos dibuixos? Quina era (és) la syscall per gestionar la zona ratllada a Unix (Linux)? I a Mach?
Resposta
-
A POSIX (i per tant, s’implementa tant a Linux com a BSD), es defineix una system call per gestionar la memòria de manera semblant a Mach. Quina és? Quina funció de més alt nivel coneixes que la faci servir? En quines circumstàncies?
Resposta
-
Explica quins advantatges veus al model actual de Linux. Creus que necessita d’un suport hardware?
Resposta
3.3. Què li va passar al Pathfinder?
-
Al juliol de 1997 es va iniciar la missió de la NASA “Mars Pathfinder” que va estar a punt de fracassar. Pocs dies després d”aterrar” el sistema va començar a patir resets. Explica en què va consistir el problema i com es va resoldre. Com a guia, mira de respondre a aquestes preguntes:
-
Quin sistema operatiu es va fer servir a la missió? Encara té suport actualment?
Resposta
-
Quin va ser el problema? Com el van poder diagnosticar?
Resposta
-
Quants threads estaven involucrats en el problema? Què feia cadascun?
Resposta
-
Com es va resoldre? Quins dels mecanismes disponibles a la llibreria de threads van fer servir?
Resposta
-
3.4. Jitter i les interrupcions
En el nostre sistema, mirem l’assignació que tenen les interrupcions a processadors (CPUs), usant el fitxer d’informació /proc/interrupts:
$ cat /proc/interrupts # mostra els comptadors d'interrupcions arribades a cada CPU
CPU0 CPU1 CPU2 CPU3
0: 115 0 0 0 IO-APIC timer # rellotge
1: 66487 0 0 0 IO-APIC i8042 # teclat
8: 0 65 0 0 IO-APIC rtc0 # real time clock
9: 0 286280 0 0 IO-APIC acpi # interprocessor interrupt
18: 0 0 0 1609132 IO-APIC i801_smbus # system management bus
40: 0 0 0 387057 PCI-MSI ahci # USB 1
41: 0 0 712702 0 PCI-MSI xhci_hcd # USB 2
42: 0 0 0 102754 PCI-MSI eth0 # xarxa
45: 926 0 0 0 PCI-MSI snd_hda_intel:card1 # soundcard
46: 0 3626057 0 0 PCI-MSI iwlwifi # wifi
47: 0 0 2897210 0 PCI-MSI i915 # tarjeta gràfica
48: 0 0 0 150 PCI-MSI snd_hda_intel:card0 # soundcard
NMI: 0 0 0 0 Non-maskable interrupts
LOC: 52380920 48263461 51959641 48009742 Local timer interrupts # rellotge per CPU
RES: 3338614 2688932 2320548 1848684 Rescheduling interrupts(*)
CAL: 4492766 4433077 4450137 4561569 Function call interrupts(*)
TLB: 4490349 4430039 4448187 4558658 TLB shootdowns(*)Fem algunes estadístiques sobre la recepció i distribució de les interrupcions:
- Totals:
CPU0 CPU1 CPU2 CPU3
64770177 63727911 66788425 61077746
- En percentatge sobre el total:
CPU0 CPU1 CPU2 CPU3
25.26% 24.85% 26.05% 23.82%(*) Aquestes interrupcions s’anomenen Inter-Processor Interrupts (IPIs), i les utilitza l’SO per enviar avisos d’un processador (CPU) a una altra i donar ordres, per exemple: “fes una replanificació (RES)”, o bé “executa aquesta funció (CAL)”, o bé “fes un flush del teu TLB, perquè he canviat l’espai d’adreces del procés on estàs executant (TLB)”.
Per donar una referència de quant de temps ha passat mentre es rebien totes aquestes interrupcions, aquest és l’uptime de la màquina:
$ uptime
16:38:31 up 2 days, 9:20, 16 users, load average: 0.07, 0.06, 0.01I aquesta és la distribució d’interrupcions per segon:
CPU0 CPU1 CPU2 CPU3
interrupcions per segon 313.8 308.8 323.6 295.9
total: 1242 interrupcions per segonTambé mirem la configuració del kernel, pel que fa a la interrupció de rellotge:
# CONFIG_HZ_100 is not set
# CONFIG_HZ_250 is not set
# CONFIG_HZ_300 is not set
CONFIG_HZ_1000=y
CONFIG_HZ=1000-
Expliqueu el tema del jitter en el sistema operatiu, com afecta als processos i també a les aplicacions paral·leles, i relacioneu-lo amb l’assignació de les interrupcions que veieu en aquesta informació prèvia que hem vist.
Resposta
-
Doneu la vostra opinió sobre si un sistema amb aquestes característiques podria servir per donar algun tipus de servei de temps real en mode hard.
Resposta
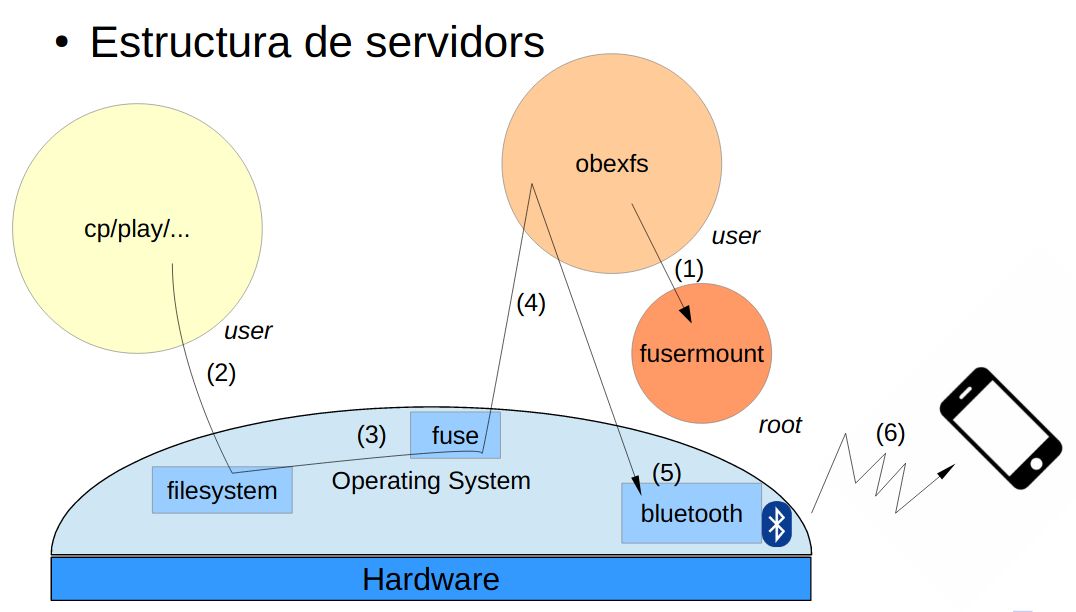
3.5. OBEX i accés a sistemes de fitxers remots
-
Explica com OBEX - Object Exchange - ens permet accedir a dades exportades per altres dispositius (ordinadors, telèfons mòbils…). Usa el següent dibuix per millorar l’explicació.
Per no haver d’entregar un dibuix, en l’explicació pots fer referència als punts numerats amb (1) .. (6)